아마 운영체제를 공부하면 '메모리 계층 구조'란 것을 배우게 될 것이다. 컴퓨터는 자원의 효율성을 위해서 이 메모리 계층 구조의 성질을 가지게 되었는데, 2022년 오늘날에도 이 구조를 계속 사용하고 있다.
이 글에서는 메모리 계층 구조에 대한 설명과 그 사용처에 대한 예시를 쓰고자 한다. 기술 면접 준비나 운영체제에 대해 더 자세히 알고 싶다면 한번 읽어보길 바란다.
폰 노이만 구조

먼저 메모리 계층 구조를 알기 전 이 폰 노이만 구조를 알아뒀으면 한다. 폰 노이만 구조는 CPU, 메모리, 입력장치가 하나의 버스로 연결되어 있는 구조를 말한다. 이 구조가 등장하기 전에는 전선을 연결하는 형식으로 되어있어서 다른 용도로 사용하려면 전선 연결을 바꿔야 했다.
이 구조에서 가장 중요한 특징은 '모든 프로그램은 메모리에 올라와야 실행할 수 있다'는 것이다. 즉 어떤 프로그램이 동작하기 위해서는 제일 먼저 메모리에 존재해야 한다. 그래서 이 메모리를 효율적으로 사용하기 위해 메모리 계층 구조가 등장하게 되었다.
메모리 계층 구조
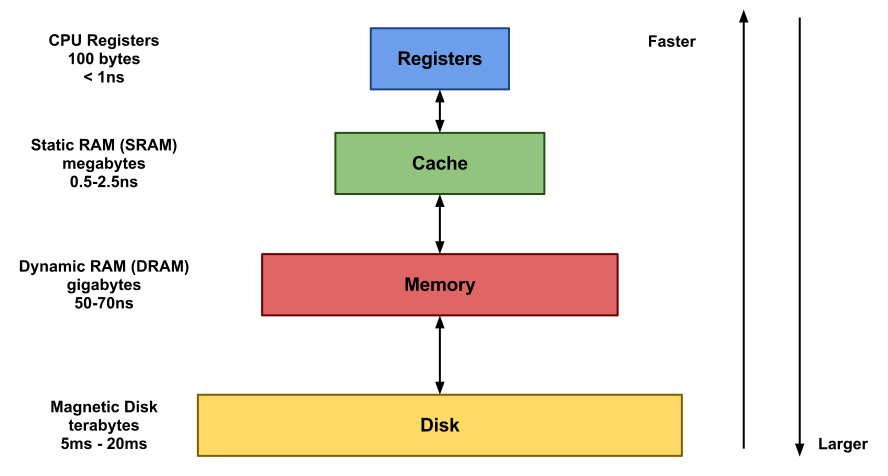
위 그림을 보면 상위부터 레지스터, 캐시, 메모리, 디스크로 구성되어 있으며 위쪽에 있을수록 더 좋은 성능을 낸다. 구조가 이렇게 형성된 이유는 비용 측면 때문인데, 레지스터만으로 고용량을 구성하려면 엄청나게 많은 비용이 나온다.
따라서 컴퓨터는 가장 많이 쓰는 작업을 상단에 두고, 적게 쓰는 작업을 하단에 두는 식으로 동작하여 효율적인 성능을 내준다. CPU는 처음에 레지스터에서 프로그램을 찾고, 없다면 캐시, 그 이후에는 메모리에서 찾는 식으로 역할을 수행한다.
레지스터와 캐시
레지스터와 캐시는 CPU에 직접 장착된 메모리로, 가장 빠른 속도를 구현한다. 이는 컴퓨터 사양을 볼 때 발견할 수 있다. 레지스터의 경우 초기에는 CPU 사양에 표기가 되었지만, 최근에는 이 레지스터 사양이 안 쓰여있다. 그러나 캐시의 경우 L2, L3 캐시 형식으로 쓰여 있는 것을 상품에서 볼 수 있다.

사진에서 보다시피 캐시의 경우 작은 용량을 가진다. 레지스터는 아마 2MB 이하로 더 작은 용량을 가질 걸로 예상된다. 그만큼 정말 자주 접근하는 프로세스만 저장되며, 여기서 찾지 못할 경우 CPU는 RAM이라는 메모리에서 찾게 된다.
메모리와 디스크

메모리 계층 구조에서 3,4 단계를 맡고 있는 부품은 RAM과 SSD다. 초기에는 SSD 대신 하드디스크가 그 역할을 했지만, SSD의 가격이 저렴해지고 용량이 커지면서 그 자리를 대체하게 되었다. 그러나 안정성과 수명이 중요한 클라우드 컴퓨터(AWS 등)에서는 여전히 하드디스크를 사용하는 추세다.
대부분의 프로그램은 3번째 단계인 메모리에서 끝이 나는 경우가 많다. 하지만 램이 작은 저사양 PC나 임베디드 시스템의 경우 디스크까지 메모리를 사용하는 경우가 있다. 이 경우 운영체제는 '가상 메모리'라는 개념을 사용하여 디스크를 메모리처럼 사용한다. 디스크 부분의 메모리를 사용할 경우 프로그램은 작동하지만, 사용자가 체감할 정도로 속도가 느려지는 것을 알 수 있다.
이걸 알아야 하는 이유는?
컴퓨터 구조론에서 지역성이라는 개념이 있다. 이는 특정 부분에 있는 데이터를 집중적으로 접근하는 현상을 의미한다. 이 지역성의 목표는 메모리 계층 구조 상위에 최대한 많이 적중시켜 접근시간을 줄이는 것이다.
아마 위 개념에 대한 설명으로 충분하지 않을 것이다. 이에 어울리는 예시로 병합 정렬과 퀵 정렬이 있다. 둘 다 O(n log n)의 시간복잡도를 가지지만, 지역성의 법칙때문에 퀵정렬이 더 뛰어난 알고리즘이다.
각 정렬에 대한 설명은 이 링크에 자세히 설명되어 있다. 그리고 이 정렬 알고리즘을 이용해서 16개의 숫자를 정렬시켜 본다고 가정해보자. 이때 레지스터는 최대 8개의 숫자를 담을 수 있다고 생각한다.
먼저 병합 정렬을 사용할 경우 매 과정에서 16개의 숫자를 전부 참고해야 한다. 레지스터가 8개의 숫자를 담을 수밖에 없기에, 계속해서 그 아랫단계인 캐시를 참고해야 한다. 이로 인해서 miss가 많이 발생하여 알고리즘 성능이 떨어지게 된다.
그러나 퀵 정렬의 경우는 처음 경우에만 16개의 숫자를 참고한다. 그 후에는 점차 참고하는 숫자가 줄어든다. 예를 들어 처음 정렬을 실행하고 8개, 7개로 나뉘었다면 좌측에 8개를 전부 레지스터에 저장하고 그 부분을 먼저 실행할 것이다. 이때는 단 한번의 미스없이 8개를 전부 레지스터에서 불러와 정렬을 할 것이다. 이후 나머지 7개를 정렬할 때 miss가 단 한번 발생하고 이 때 레지스터에 저장된 값이 7개의 숫자로 변경되는 것이다.
메모리 계층 구조에 대한 개념은 어설프게 알았지만, 좀 깊게 생각해보니 기존 지식을 활용하는 경우가 많았다. 이 내용을 숙지하고, 자신만의 방법으로 실무에 유용하게 쓰길 바란다.

댓글